Zachary W. Huang
Image Super-Resolution
Image super-resolution is the process of upscaling an image without the normal loss in detail that occurs when a standard interpolation method is used.
Below is a visual showing common interpolation methods for image upscaling.
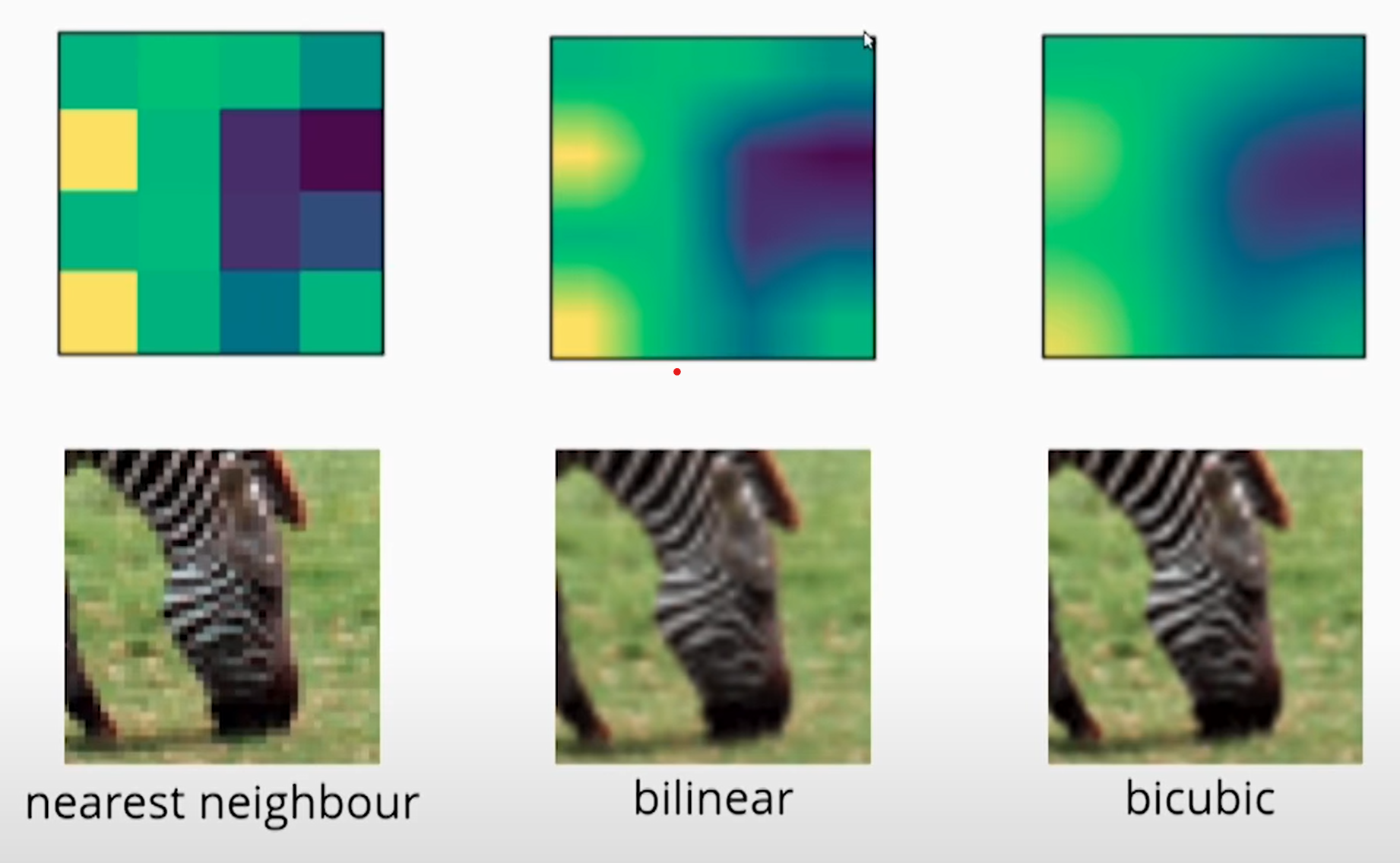
Single-image super-resolution seeks to improve upon this, using the magic of deep learning to essentially generate new pixels instead of interpolating between existing ones.
Deep Learning
Deep learning is the use of a neural network to model some function of input data to output data.
In the case of image super-resolution, consider the function .
is the neural network, and we provide it with an input image and weights. The goal is for the output image to be a super-resolved version of the input.
We can “train” the network to do super-resolution by giving it an input image, checking to see how close is to the true super-resolved image (the label or target), then nudging the weights in a way that improves the neural network’s original guess.
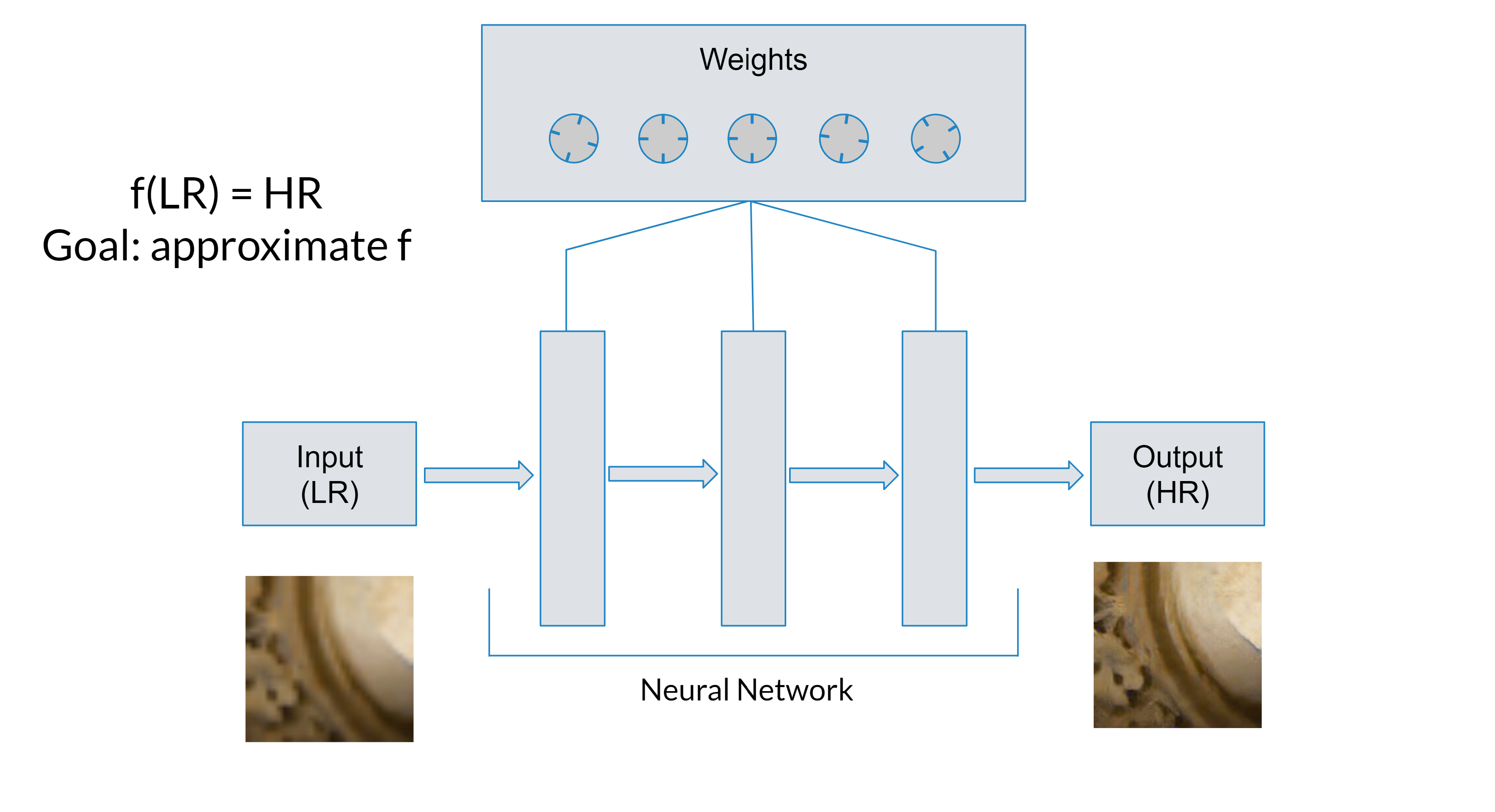
This is glossing over many details (see gradient descent, backpropagation), but the process generally “just works”.
Convolutional Neural Network
A convolution is the basic image processing unit that is used in neural networks which input/output images. A single convolution has the same signature presented above: . Because of this, we can chain together convolutions to create, you guessed it, a convolutional neural network, in which the overall parameter is just a tuple of weights for each individual convolutional layer.
Single-image Super-resolution
As part of a research magnet program, I conducted two research projects on single-image super-resolution using deep learning (one during sophomore and junior year).
The first one I did focused on applying ensemble learning (when multiple neural networks are trained and used together) to super-resolution. The paper for that can be found here. The code can be found here.
The second focused on a specific type of convolutional layer called a partial convolution. That paper can be found here. The code can be found here.


Zachary W. Huang © 2021-2025